
地球online攻略 应用数据 1 API 与 Web scraping
最近团内有些小伙伴经常对于此类问题有疑惑,所以才开了这篇文章。希望不仅在率土之滨中,也能在生活和学习中分享一些经验
此文章写给对此内容感兴趣的但是还没入门或者是想报类似的班和专业但是还没决定好的朋友
如果你是大佬请轻轻划走,因为这都是很基础的知识,有些人自学也可以达到,不是难的内容
什么是数据科学(data science)?
数据科学是任何涉及处理大量数据的研究领域的总称
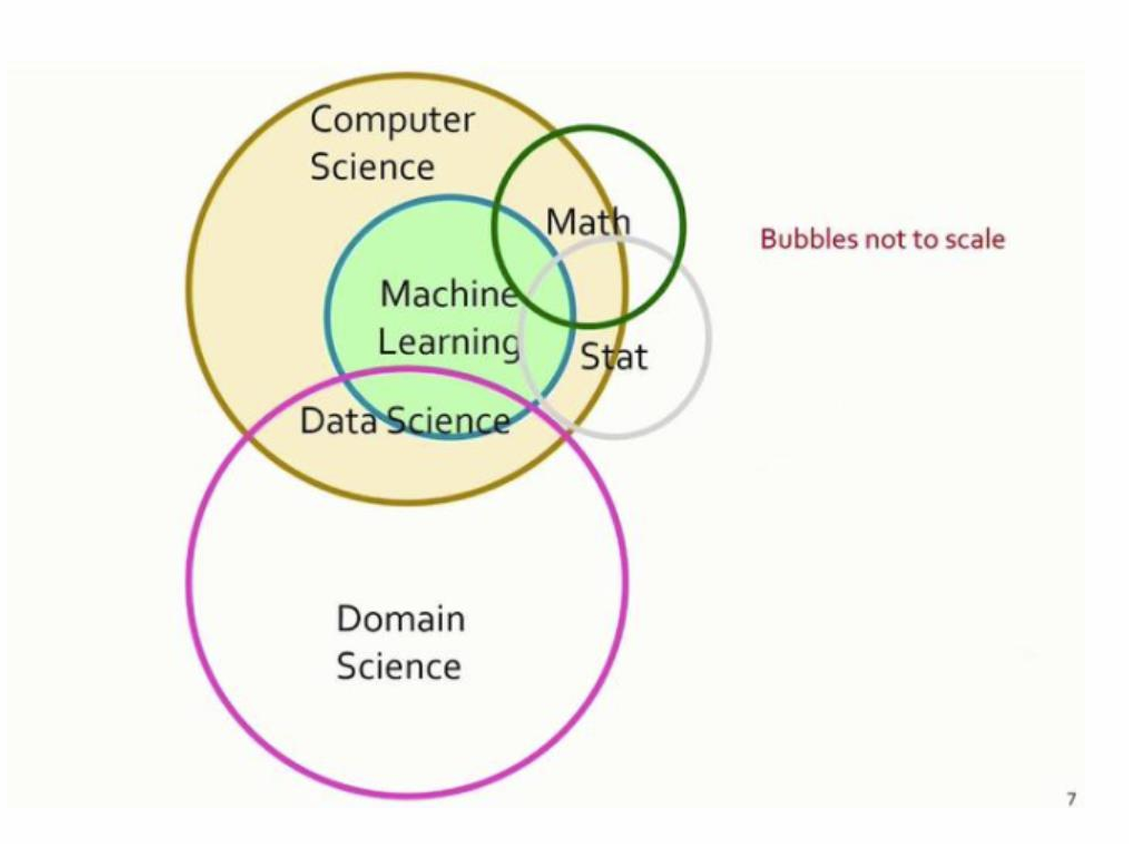
为什么我们需要应用数据?
具体到率土中,盟主利用数据解决各种同盟问题
我们经常处理小型数据集,而不仅仅是大量数据集
数据科学提供了强大的计算技术 为数据建模并揭示隐藏的模式
这种方法有助于我们
– 加深对战术和缺勤问题的理解
– 基于证据的知情决策
– 建立有效的预防盟友犯罪的应用程序
如果应用到生活中,可以帮助我们找到相对应的工作。包括但不限于:
– 数据分析师
– 大语言模型开发或测试员
– 国家或安保公司安全分析师
争取成为数据科学的关键消费者
首先我们将从如何从网络收集数据开始讲起
现有的几种方式:
数据以可下载格式提供,并向公众开放 如国家统计局
人工方法 费时、易出错、不实用
自动化方法
– 应用编程接口(API)
– 网页抓取 Web scraping
Application programming interface (API)
帮助软件程序相互通信和检索数据的编程代码集合 大多数应用程序接口都有文档(开发人员手册),说明如何使用 如何使用应用程序接口、它提供的服务和限制
API是如何工作的?
1. 提出请求
2.客户端向 API 服务器发送请求
3.API 服务器处理请求,从 数据库
4.将数据发送给客户端
应用程序接口协议
– 计算机的协议定义了如何进行交互和相互理解:它们定义了规则和限制。它们定义了通信的规则、限制和局限。和限制。
– 网络 API:通过浏览器使用 HTTP(超文本传输协议
协议)通过浏览器访问
流行的应用程序接口架构和协议: REST、SOAP 和 RPC
举例:卫报 API 安装和请求数据
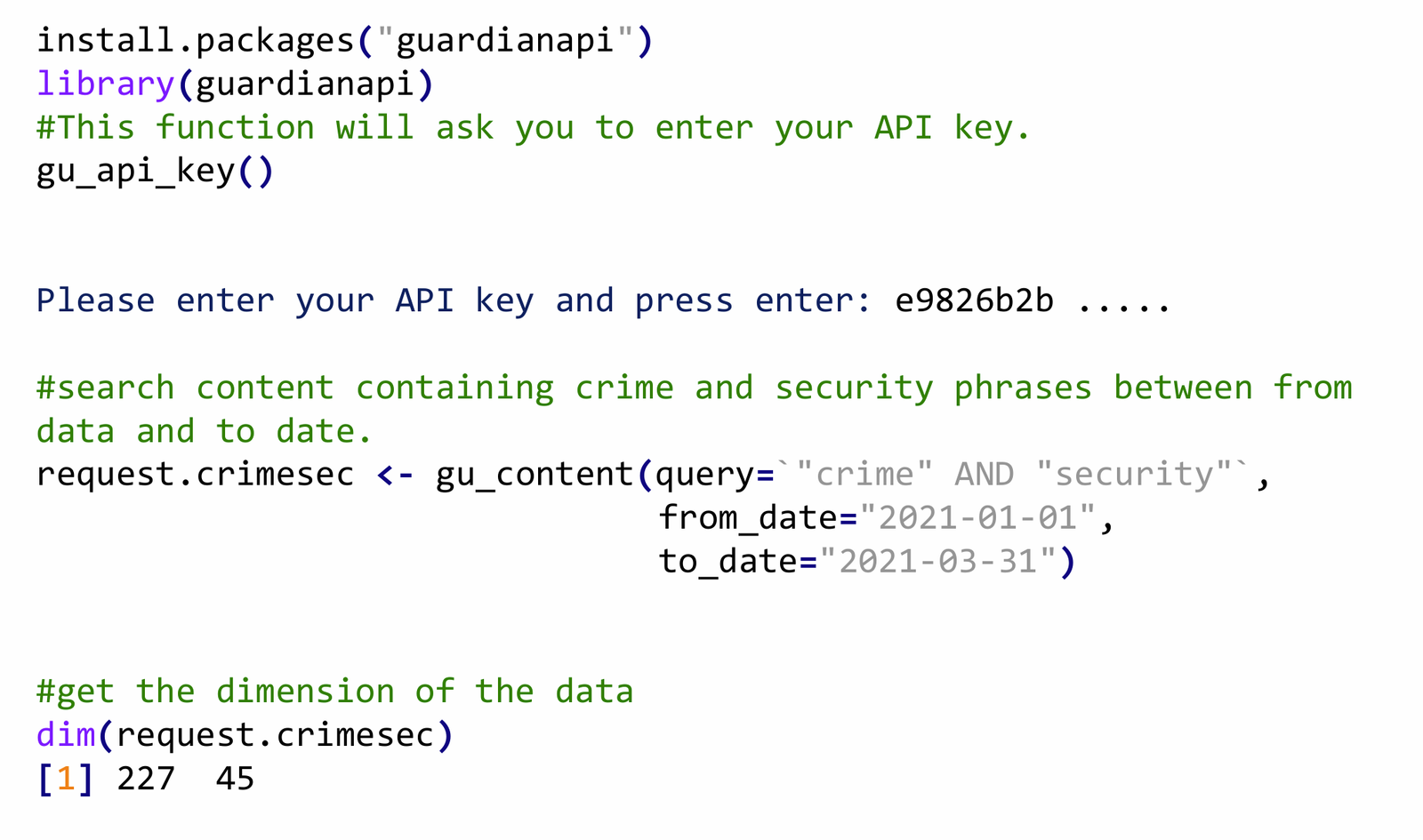
获取对象名称

到此只是最最基础的皮毛中的皮毛,更深入地使用方法或感兴趣具体操作流程和想实操演练的可以咨询我
下面我们来讲Web Scraping
自动从网页中提取非结构化数据并将其转化为结构化数据集的过程 进行分析
– 两个主要步骤
1) 获取(下载)包含数据的 HTML 页面(源代码的 HTML 页面
2) 从 HTML 网页中提取相关数据
网络搜刮是自动从网站上提取特定内容并将其转化为结构化数据的过程。
– 耗时
– 需要学习才能掌握
– 不同的网站会有不同的结构,网站也会变化、
需要重写代码
– 网站可能会禁止刮削
一个简单的 HTML 页面:
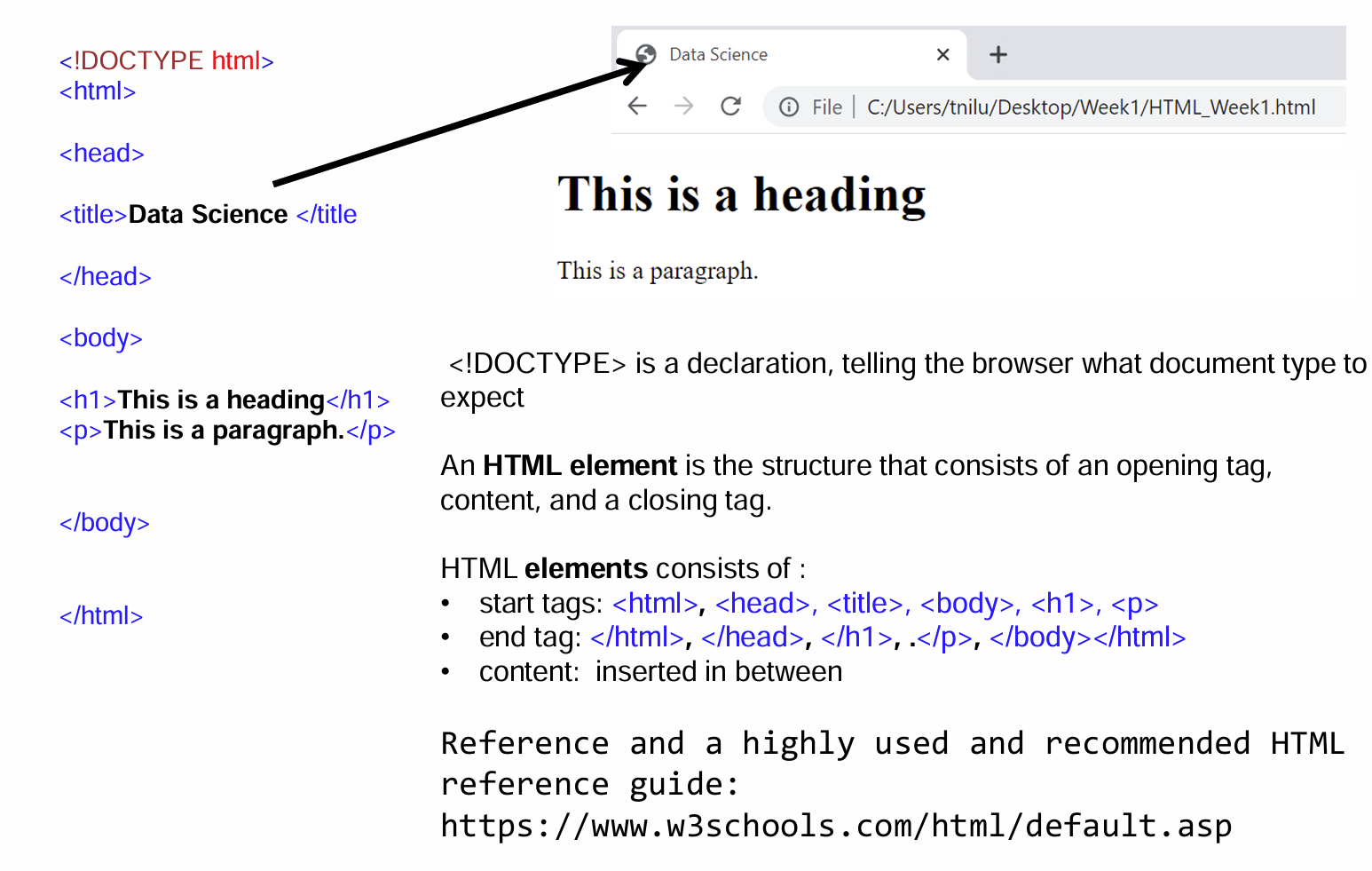
在 HTML 文档中添加 CSS
在 HTML 文档中应用 CSS 有三种方法:
1) 内联 – 在 HTML 元素内使用样式属性
2) 内部 – 作为 html 文档的一部分,在标题 部分的一部分。
3) 外部–作为一个单独的 CSS 文件,在 html 文件中调用。

R语言中的网页抓取
– rvest 是一个 R 软件包,可帮助从网页中抓取数据
– 非常流行,有大量在线资料和帮助
vest 的更多信息,请访问 CRAN 上获取:https://cran.r-project.org/web/packages/rvest/index.html
– read_html( ): 读取 HTML 页面(”通过执行 HTTP 请求,然后 使用 xml2 包解析接收到的 HTML”)
– html_element( ) 或 html_elements( ): 使用 CSS 选择器查找 HTML 元素
– html_table( ): 将 HTML 表格解析为数据框架
– html_attr( ):获取单个属性
– html_text( ): 原始底层文本
– html_text2( ):模拟文本在浏览器中的显示效果
使用 rvest 进行网络搜刮: 联邦调查局网络通缉犯
目标 URL:https://www.fbi.gov/wanted/cyber
这是一个fbi相关的网站,上面拥有很多罪犯的信息
网络搜索的核心步骤
– 检查网页
– 决定要从以下网页中抓取的数据 的数据
– 确定 CSS 选择器:
– 使用 浏览器
– 其他工具(如 selectorGadget)
– 使用 rvest 软件包编写程序
使用 rvest 进行网页抓取的步骤
1. 安装并加载 rvest 库
2. 使用函数 read_html( ),指定您要抓取的网页的 URL,将网页读取到 R 中。函数 read_html() 将网页读入 R
3. 使用函数(html_element( )、html_elements() 函数(html_element()、html_elements())和 CSS 选择器从 HTML 文档中提取指定元素。
最后可以使用一些函数提取元素的组成部分
至此最最基本的API与Web scraping的知识和浅显的操作流程已经结束
如果你觉得文章有用或者感兴趣,请一键三连